
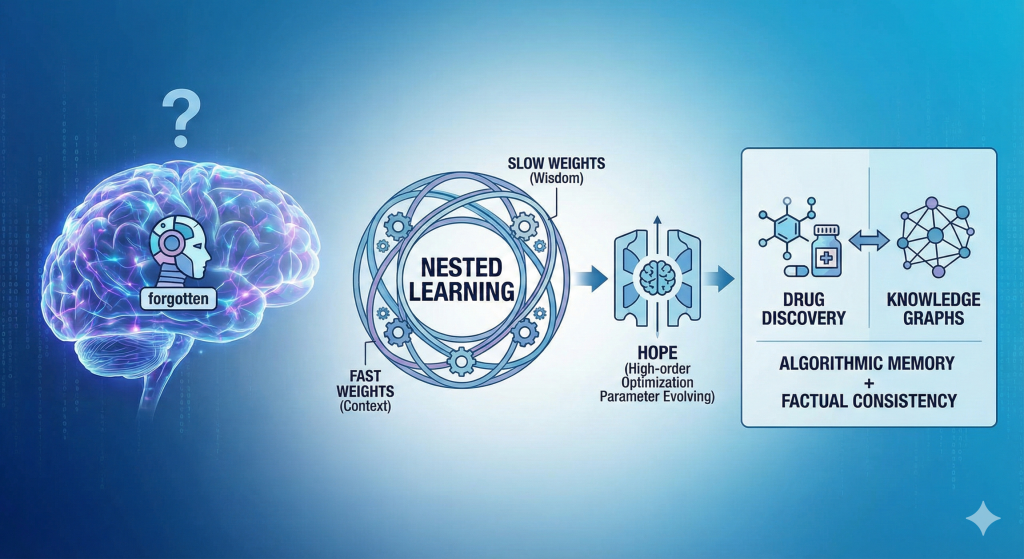
Google Research just released a fascinating new paradigm called “Nested Learning” to solve one of the most persistent headaches in AI: “catastrophic forgetting.”
In traditional machine learning, models are often static.
When you teach them a new task, they tend to overwrite what they learned previously. To learn the “new,” they forget the “old.”
Google’s solution is elegant because it mimics the human brain.
Instead of treating a model as a single flat network, Nested Learning views it as a hierarchy of loops.
• Fast weights handle immediate context (like short-term memory).
• Slow weights consolidate long-term structural wisdom.
They even introduced a new architecture called HOPE (High-order Optimization Parameter Evolving) that essentially “learns how to learn,” modifying its own update rules on the fly to retain information better.
Think about the pain of training a model on kinase inhibitors and then trying to extend it to GPCRs.
Currently, you often have to choose between retraining from scratch or accepting that your model will lose its expertise on kinases as it learns the new target.
This capability is absolutely crucial in biomedical science and drug discovery.
We are still uncovering vast amounts of knowledge about human biology. New treatments keep coming out, and the frontiers of disease treatment keep changing.
We need to constantly update our models to capture these shifting frontiers.
However, if every update causes the model to “forget” established science, the model’s overall performance inevitably degrades. We end up with AI that fluctuates rather than improves.
Nested Learning proposes a future where models genuinely accumulate knowledge across therapeutic areas, assay types, and patient populations without degrading their earlier expertise.
This is where I see a powerful synergy with Knowledge Graphs.
While Nested Learning improves how algorithms retain patterns and “process” information, Knowledge Graphs provide the structured, factual “long-term memory” that grounds these models in scientific reality.
One solves the algorithmic memory problem. The other solves the factual consistency problem. Together, they could move us away from static tools and toward AI that truly evolves with the science.
How do you currently handle model retraining without losing historical insights?
#DrugDiscovery #AI #DeepLearning #GoogleResearch #Bioinformatics #Pharmacovigilance